



حافظههای با پهنایباند بالا؛ پاسخی به نیازهای فناورانه نوین
زاویه؛ امروزه فاصله عملکردی میان پردازنده و حافظه به یک چالش قابل توجه در سیستمهای محاسباتی مدرن تبدیل شده است. سرعت پردازندهها به طور مداوم در حال افزایش بوده و از سوی دیگر تأخیر حافظه نسبتاً ثابت باقی مانده است. اگر زمان قابلتوجهی صرف انتظار برای واکشی[1] دادهها از حافظه شود، عملکرد کلی سیستم که با توجه به سرعت جابهجایی دادهها بین پردازنده و حافظه تعیین میشود، دچار افت خواهد شد. افزایش تقاضا برای کاربردهای دادهبر[2] مانند هوش مصنوعی، یادگیری ماشین و تحلیل کلان دادهها نیز مشکل تأخیر را تشدید کرده است. در این برنامهها که نیازمند پردازش حجم عظیمی از دادهها هستند؛ نیاز است که دادهها به صورت مکرر بین پردازنده و حافظه جابهجا شوند. این جابجاییهای پرتکرار دادهها سبب تأخیری میشود که میتواند بر عملکرد برنامههای دادهبر تأثیر منفی بگذارد.
از سوی دیگر انرژی مصرفشده برای پردازش و ذخیره موقت دادهها در پردازندههای پیشرفته به سطحی رسیده که سبب ایجاد محدودیتهایی در این حوزه شده است. به عنوان مثال میتوان به بررسی ریزتراشۀ هوش مصنوعی «H100» متعلق به شرکت «Nvidia» پرداخت. در صورتی که بهطور متوسّط از 61 درصد قدرت پردازش این تراشه در طول سال استفاده شود، توانی حدود 700 وات را مصرف خواهد کرد؛ رقمی که تقریباً برابر متوسّط توان مصرفی یک خانوار (متوسّط جمعیت خانوار 2.51 نفر فرض شده) است. این در حالی است که یک سرور هوش مصنوعی به راحتی ممکن است به چند هزار ریزتراشه «H100» نیاز داشته باشد.
علاوه بر این، با عرضه هر نسل جدید از فناوری تولید ریزتراشههای منطقی، اجزاء آن کوچکتر شده و میتوان همان عملکرد را در مساحت کمتری و در ریزتراشه کوچکتری محقق ساخت؛ بهعبارتدیگر تراکم اجزاء ریزتراشه در هر نسل بیشتر میشود. در گذشته افزایش تراکم در ریزتراشههای حافظه سریعتر از پردازندهها بود اما در سالهای اخیر افزایش تراکم در ریزتراشههای حافظه با موانع جدّی روبرو و تقریباً متوقف شده است.
این در حالی است که حجم حافظه مورد نیاز به سرعت رو به افزایش است. شکل 1 نشاندهندهی این واقعیت است که از سال 1980 تا سال 1995 هر سه سال یکبار تراکم در حافظه تصادفی پویا[3] که بهاختصار «DRAM» نامیده میشود، چهار برابر شده است. از سال 1995 تا سال 2010 هر دو سال یکبار تراکم به دو برابر افزایش یافته است و از سال 2010 به بعد روند دو برابر شدن تراکم به هر چهار سال یکبار رسیده است.
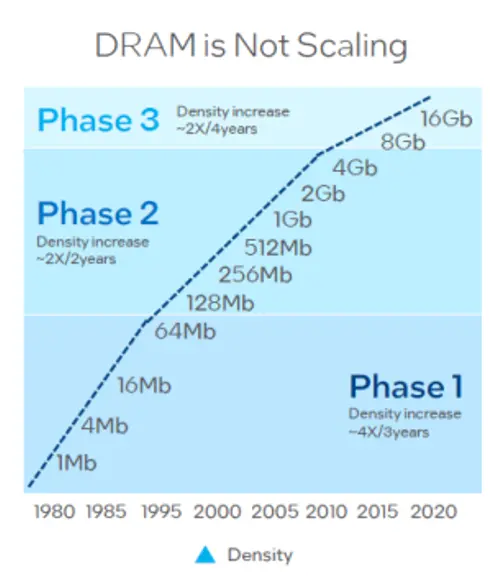
شکل 1: روند افزایش تراکم حافظه «DRAM» (تعداد بیت بر واحد سطح)
برای رفع مشکلات ذکر شده در تراشههای حافظهی سنتی، حافظه با پهنایباند بالا[4] (HBM) تولید شده است. توسعه این نوع تراشهها از سال ۲۰۰۸ توسّط شرکت «AMD» ایالاتمتحده و «SK Hynix» کرهجنوبی آغاز شد و در سال ۲۰۱۳، این شرکتها مشخصات مربوط به تراشه را در اختیار انجمن فناوری حالت جامد جِدِک (JEDEC)، نهاد مرجع تدوین ضوابط و استانداردها برای تولید محصولات میکروالکترونیک، قرار دادند. «HBM» در واقع همان حافظه تصادفی پویا محسوب میشود که بستهبندی و ارتباط بین آن و پردازشگر مبتنی بر استاندارد «JESD238A»، متعلق به نهاد مذکور است.
پیش از این که به بررسی معماری حافظه با پهنایباند بالا بپردازیم، لازم است ابتدا درکی از عبارت پهنایباند حافظه به دست آوریم. به زبان ساده، پهنایباند حافظه نرخی است که در آن دادهها میتوانند توسط یک پردازنده از حافظه خوانده یا در آن ذخیره شوند. پهنای باند حافظه به فرکانس ساعت[5] و پهنای گذرگاه[6] و حجم داده مبادله شده با هر پالس ساعت بستگی دارد. همانطور که روزبهروز برنامهها پیچیدهتر میشوند، نیاز به پهنایباند بالاتر نیز افزایش مییابد. معماری و ساختار حافظه با پهنایباند بالا بر پایه یک رویکرد نوآورانه و سهبعدی استوار است که به منظور دستیابی به سرعتهای بالای انتقال داده و کاهش مصرف انرژی طراحی شده است. ساختار «HBM» از چندین (حداقل 4) لایه تراشه حافظه تصادفی پویا تشکیل شده است که از طریق کانالهای عمودی به نام «TSV»[7] (میانراههای سیلیکانی) به یکدیگر متصل میشوند. لایههایی که به صورت عمودی روی هم قرار گرفته و یک بلوک سهبعدی را تشکیل میدهند. «TSV» ها در واقع حفرههای کوچکی هستند که درون سیلیکان حفر میشوند تا ارتباط تراشههای روی هم را با سرعتهای باورنکردنی میسر سازند و باعث به حداقل رسیدن تأخیر شوند.
این چندلایه از تراشههای حافظه نیز از طریق میانراههای سیلیکانی به یک دای منطقی[8] متصل میشوند که این دای وظیفهی کنترل این تراشهها را بر عهده دارد. کل پکیج ذکر شده (لایههای حافظه و دای منطقی) بر روی لایهای به نام اینترپوزر[9] قرار میگیرد. اینترپوزر در واقع یک صفحه سیلیکانی است که به عنوان پایهای برای نصب تراشههای «HBM» عمل میکند. این قطعه نهتنها به عنوان یک واسط برای اتصال حافظه به پردازنده یا سایر اجزای سیستم عمل میکند، بلکه به توزیع یکنواخت حرارت در سراسر بسته حافظه کمک میکند؛ امری که طول عمر و قابلیت اطمینان سیستم را افزایش میدهد. اینترپوزر این امکان را فراهم میآورد که «DRAM»ها بدون اینکه در همان دای قرار داشته باشند، در نزدیکی بسیار زیادی به پردازندههای «GPU»، انواع «CPU» و «APU» قرار گیرند.
این نزدیکی سبب چندین مزیت مهم از قبیل دسترسی به پهنایباند بالاتر و مصرف انرژی کمتر میشود. همچنین وجود اینترپوزر سبب میشود که انواع پردازندهها و تراشههای حافظه بتوانند از نسلهای مختلف فناوری (به طور مثال پردازندهای از نسل فناوری 28 نانومتر در کنار حافظهای از نسل فناوری 18 نانومتر) باشند. برای اتصال لایههای مختلف به یکدیگر نیز از میکروبامپ[10]ها (یک برجستگی کوچک برای اتصال دو تراشه به یکدیگر) استفاده میشود. در شکل 2 نحوهی چگونه قرار گرفتن لایهها در یک «HBM» قابل مشاهده است.
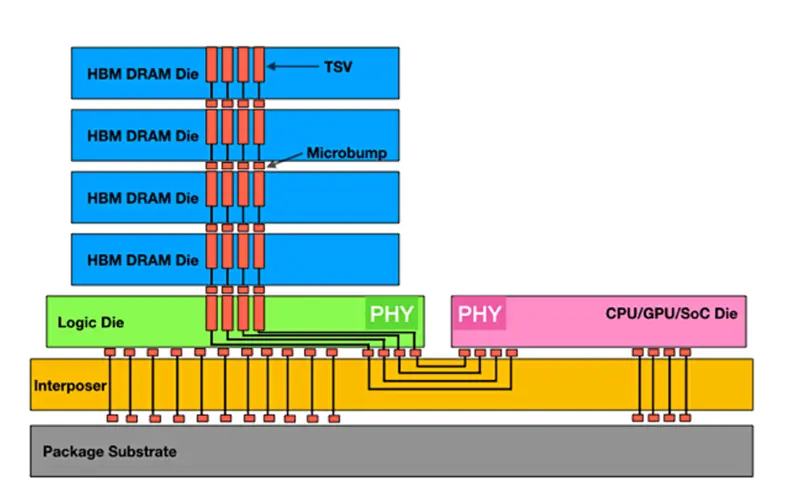
شکل 2: نحوهی چگونه قرار گرفتن لایهها در یک حافظه با پهنای باند بالا
میتوان «HBM»ها را از جنبههای مختلفی با کارتهای حافظهی فعلی مورد مقایسه قرار داد. پیش از ظهور استاندارد تراشههای حافظه با پهنایباند بالا، استاندارد «GDDR6»[11] مطرح بود که بیشتر برای کارتهای گرافیک بازیهای رایانهای استفاده میشد. «GDDR» برای هر دای نیازمند یک گذرگاه حافظۀ جداگانه بود و این اقدام مجتمع کردن تعداد زیادی دای در اطراف واحد پردازش مرکزی را غیرممکن میکرد. این در حالی است که در معماری «HBM» بهنحوی است که چندین دای رویهمقرار گرفته[12] و از طریق «TSV»هایی که به یکدیگر متصل هستند، در مجاورت پردازنده قرار میگیرند.
رویهم قرار دادن چندین تراشه حافظه به صورت عمودی، سبب کوتاه شدن مسیرهای ارتباطی میگردد؛ امری که موجب افزایش سرعت انتقال دادهها خواهد شد. از دیگر تفاوتها میتوان به گذرگاه بسیار عریضتر «HBM»ها اشاره کرد که امکان انتقال دادهها به صورت موازی را فراهم میآورد. این امر باعث میشود که دادههای بیشتری به طور همزمان منتقل شوند. در مقابل گذرگاههای تراشههای سنتی باریکتر هستند و این مسئله در سرعت تبادل دادهها محدودیت ایجاد میکند.
تراشههای «HBM» دارای پهنای گذرگاه 1024 بیت به ازاء هر پشته هستند؛ در حالی که این عدد در استاندارد «GDDR5» فقط 64 بیت است. به همین دلیل در تراشههای مذکور میتوان با فرکانس ساعت کمتر، حجم دادۀ بیشتری را جابجا کرد. بایستی توجه داشت که فرکانس ساعت کمتر منجر به کاهش قابل توجّه برق مصرفی به ازاء هر بیت خوانده یا نوشته شده در حافظه میشود. از دیگر تفاوتهای قابل توجه، کمتر بودن ولتاژ کاری و مصرف انرژی «HBM»ها نسبت به حافظههای سنتی است. به دلیل آنچه ذکر شد، استفاده از این تراشهها منجر به کاهش حدود 40 درصد مصرف توان و افزایش حدود 65 درصد کارایی میشود. شکل 3 به مقایسه «HBM» با یک تراشه حافظه «GDDR5» پرداخته است.

شکل 3: مقایسهی «HBM» با تراشه حافظه «GDDR5»
در پایان بایستی اذعان کرد که «HBM»ها به عنوان یک نوآوری حیاتی در عرصه ساخت تراشه حافظه ظهور پیدا کردهاند؛ به طوری که توانستهاند با معماری بدیع، کارایی انرژی و سرعت بیمانند خود به نیازهای روزافزون فناوریهای مدرن پاسخ دهند. پیش از رواج فناوری هوش مصنوعی، سهم این تراشهها از بازار «DRAM» حدود 1.5درصد بود؛ امّا هماکنون ارزش بازار آن به حدود 2 میلیارد دلار در سال رسیده است و پیشبینی میشود که این رقم تا 2028 به 6.3 میلیارد دلار برسد. در حال حاضر، 53 درصد بازار «HBM» در اختیار شرکت «SK Hynix»، 38 درصد متعلق به سامسونگ و 9 درصد آن در اختیار شرکت «Micron» است. با رونمایی از نسلهای جدید این فناوری یعنی «HBM2» در سال 2016 با 8 لایه، «HBM3» در سال 2023 با 12 لایه و ظرفیت 24 گیگابایتی و تلاش برای رونمایی از جدیدترین نسل آن یعنی «HBM4» تا سال 2025، میتوان اظهار داشت که این نوع از حافظهها بدون شک سنگبنایی برای نوآوریهای فناوری آینده خواهند بود.
منابع:
https://techovedas.com/what-is-high-bandwidth-memory-hbm
https://hexus.net/tech/news/graphics/83221-amd-spills-details-hbm-memory/
https://bit-tech.net/reviews/tech/memory/an-overview-of-high-bandwidth-memory-hbm/1/
[1] fetching
[2] Data intensive application
[3] Dynamic Random Access Memory(DRAM)
[4] High Bandwidth Memory(HBM)
[5] clock
[6] bus
[7] through silicon via
[8] Logic Die
[9] interposer
[10] micro bump
[11] graphics double data rate
[12] stack
مطالب مرتبط



